Building Medallion pipelines with ELTMaestro¶
How to design Bronze → Silver → Gold ("medallion") data pipelines in ELTMaestro, mapped to the actual step types you place on the Job editor canvas. Part of the User Guide.
What "medallion" means here¶
The medallion pattern organizes a data platform into three quality tiers:
| Layer | Purpose | Grain |
|---|---|---|
| 🥉 Bronze | Raw landing — capture source data as-is, append-only | Source-shaped, untransformed |
| 🥈 Silver | Cleaned, conformed, deduplicated, validated | Conformed/entity-level |
| 🥇 Gold | Business marts & serving aggregates | Business-grain, read-ready |
ELTMaestro implements medallion by convention, not as an enforced construct. The engine has no built-in notion of layers — you impose the discipline through job naming / tags, schema-per-layer naming, and JobStep chaining. Each layer is one (or more) workflow; the tiers are how you organize and promote between them.
Where the layers live — your target data warehouse¶
All three layers — Bronze, Silver, and Gold — live inside the chosen target ("vendor") data-warehouse platform: Redshift, Snowflake, ClickHouse, SparkSQL (HDFS/Hive), Synapse, Databricks, Greenplum, and the rest. ELTMaestro does not host the medallion itself — it builds and orchestrates it on the warehouse, typically as a schema or database per layer (bronze_* / silver_* / gold_*) all within that one platform. You pick the platform per workflow via its Job Type + platform connection (Creating a workflow).
ELTMaestro's job is the movement and the logic on top of it:
- Land (Bronze / ingest). Extraction steps pull from heterogeneous sources and land the raw data into an ingest / landing area on the warehouse, as-is and append-only:
Jdbcsource— extract from any JDBC source database;Onstagegroup— stage files and register them as external tables in the warehouse catalog (Spark/Hive);- General-connection extracts —
Datasource(Corelli streaming) and the connector extracts (Mongo, Salesforce, SFTP, local/remote files) that reach a source through a General / Cloud connection. For MPP targets the landing typically stages through object storage ($OBJECT_STORAGE) and loads into the warehouse. - Build up (Silver → Gold). From that landing area you run the data-quality gates and the upper layers entirely inside the warehouse — conform/clean/validate into Silver, aggregate into Gold — using ELTMaestro's transform + load steps, which push the SQL/Spark work down to the platform.
So the shape is always: extract → land on the warehouse → build DQ + Silver + Gold there. Per-platform wiring is in Redshift / SparkSQL / ClickHouse / MPP setup.
Layer → step mapping¶
Every item below is a real step type from the step palette.
🥉 Bronze — raw landing / ingestion¶
| Need | Steps |
|---|---|
| Pull / extract | Jdbcsource, Datasource (Corelli streaming source), Local_file, Sftp, Pullfile; connector extracts (Mongo / Salesforce) |
| Land into the warehouse | Onstagegroup (stages files → external tables in the Spark/Hive catalog), FileStage / File_Stage, Jdbctargethdfs (object-storage staging via $OBJECT_STORAGE); for MPP targets the staged data is then loaded into the warehouse's landing area |
| Arrival triggers | FileWatch, FileScanner, RemoteFileScanner, JdbcWatch |
| Incremental capture | Watermark + the isCDC / $QUERY_CDC_* delta primitive |
Principle: capture faithfully, transform minimally, append-only. Use a Watermark so each run lands only new data; write to insert-only targets so Bronze stays immutable.
→ Deep dive: Bronze — ingestion & landing
🥈 Silver — cleaned, conformed, validated¶
| Need | Steps |
|---|---|
| Clean / shape | Filter, Dedupe, Function / Function2 (derivations), Datamask (PII), View, Pivot |
| Conform / integrate | Join, Union, Minus, Transformer, SparkDataCache |
| Historize dimensions | SCD1, SCD2 |
| Merge / upsert | OnstageDelta; onstage group loaders with the isCDC / $QUERY_CDC_DELETE + $QUERY_CDC_INSERT delete-then-insert primitive |
| Quality gate | ControlTest, SQLMetrics, MetaProfile, WriteIncident (quarantine bad rows) |
Principle: Silver is idempotent and re-runnable — dedupe, conform to canonical types/keys, and gate promotion on data quality (see the Silver quality gate). Column work happens in each step's expression builder.
→ Deep dive: Silver — clean, conform, validate
🥇 Gold — business marts / serving¶
| Need | Steps |
|---|---|
| Aggregate / model | Aggregate, Aggregate2, Table (GeneralSQLTable), group loaders |
| Publish to serving MPP | JdbcTarget{Redshift,Snowflake,Synapse,Clickhouse,Greenplum,Netezza,Yellowbrick,Exasol,Databricks}, WriteJdbc, WriteFile, Export |
| ML feature/serving | MLFeatureEngineer, MLFeatureTrainer, MLFeaturePredictor |
Principle: Gold is business-grain and serving-optimized — pre-aggregated facts/marts the BI and ML layers read directly.
→ Deep dive: Gold — aggregate & serve
The orchestration spine¶
What turns three layers into one end-to-end pipeline:
- Chaining layers —
JobSteplets a Bronze workflow invoke Silver, which invokes Gold (one orchestrating DAG, or three workflows wired by JobStep).Switch/SetVariable/Synchandle conditional flow and barriers. - Scheduling per layer — Administration ▸ Scheduler (cron): e.g. Bronze hourly, Silver/Gold on completion. See Menus.
- Alerting — Email Alerts on success/failure per layer.
- Layer labeling — Job Metadata tags (
bronze/silver/gold) so the Workflow(s) list organizes by tier.
The Silver quality gate¶
The Bronze → Silver promotion is where you enforce quality — the medallion pattern's core discipline:
ControlTest— assert row counts, key uniqueness, referential rules before promoting.WriteIncident— route failing rows to a quarantine/incident table instead of silently dropping or poisoning Silver.SQLMetrics/MetaProfile— capture column profiles and run metrics for observability.Watermark— drive incremental Silver builds so only new/changed Bronze rows are reprocessed.
Governance & observability¶
- Metrics — per-step
SQLMetrics, surfaced through Runtime & Logs ▸ Logging ▸ Workflow Logs.
Design principles (the conventions to enforce)¶
- Append-only Bronze. Insert-only targets + watermarks; never mutate raw.
- One layer per job, chained by
JobStep; tag each job by layer. - Gate Silver on quality (
ControlTest+WriteIncidentquarantine) before promoting. - Idempotent, re-runnable steps — watermarks + upsert (
OnstageDelta/ SCD) so re-runs converge. - Schema-per-layer naming (e.g.
bronze_*/silver_*/gold_*schemas or databases) to keep tiers separable. - Honest gap: ELTMaestro enforces none of this — there is no first-class "medallion" object. It's design discipline, and these conventions are how you keep the tiers clean.
A worked example — HR headcount mart¶
A small end-to-end medallion pipeline, built as three workflows chained by JobStep:
1. Bronze — land raw HR data (bronze_hr, tagged bronze)
- Jdbcsource (or Datasource) pulls Employee and EmployeeDepartmentHistory from the source system.
- Watermark scopes each run to new/changed rows; targets are insert-only (Jdbctargethdfs / Onstagegroup), so Bronze stays append-only.
2. Silver — conform & validate (silver_hr, tagged silver)
- Join the two Bronze tables into a conformed employee_department_joined; Dedupe removes duplicates; a Function2 step derives/cleans columns; SCD2 historizes the department dimension.
- A ControlTest asserts key uniqueness and row counts; WriteIncident quarantines failing rows rather than letting them into Silver.
- This is exactly the shape of the join → dedupe → function transform DAG shown in Designing the DAG:
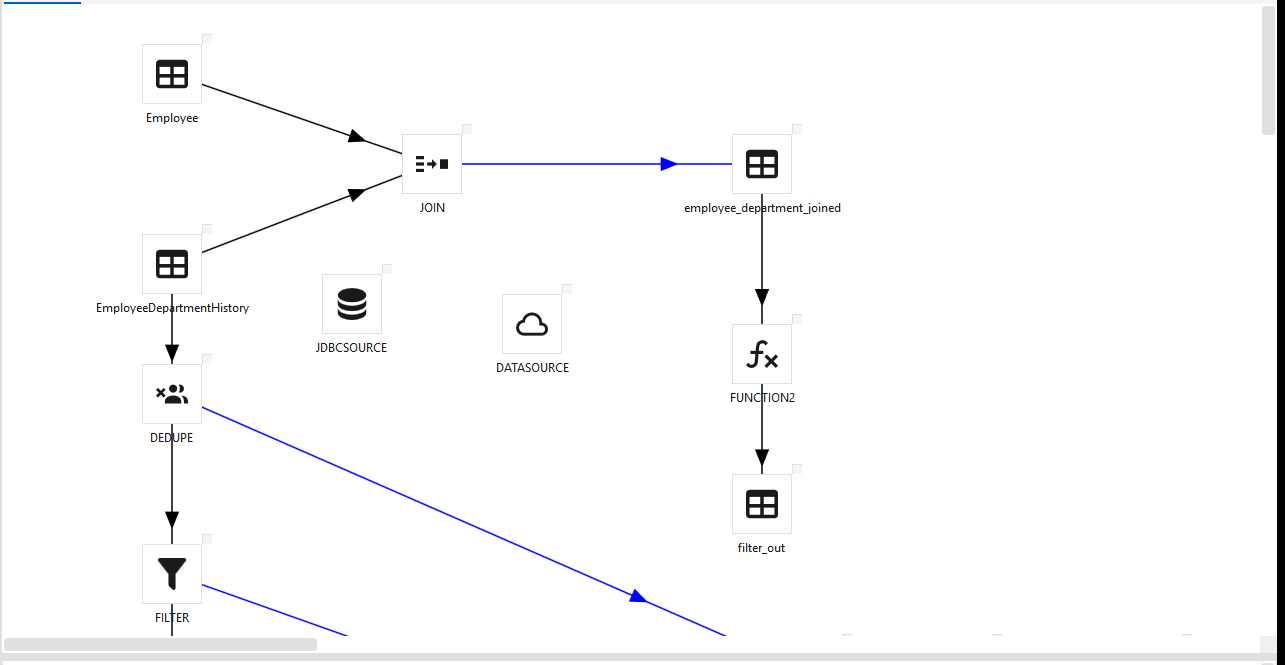
3. Gold — build the mart (gold_hr, tagged gold)
- Aggregate2 rolls Silver up to headcount-by-department; Table (or a group loader) writes the gold_headcount mart; JdbcTargetClickhouse (or your serving MPP) publishes it for BI.
Spine: a master workflow uses JobStep to run bronze_hr → silver_hr → gold_hr in order; the Scheduler runs Bronze hourly and triggers the rest on completion; Email Alerts notify on failure.
Where to build a runnable reference¶
A local ClickHouse + Spark/HDFS + Postgres stack supports an end-to-end medallion demo: files → Bronze (lake external tables) → Silver (conform in ClickHouse/Spark, gated) → Gold (Aggregate2 + JdbcTargetClickhouse), chained by JobStep, scheduled + alerted.
Related¶
- Workflows — building & running jobs · Administration & connections · Menus
- Function catalog
- Per-platform setup: Redshift · SparkSQL · ClickHouse